by Helena Mihaljević and Lucía Santamaría
Peer reviewed publications are undoubtedly the primary means of communicating the results of academic research. However the inconveniences of this typically lengthy and slow process have given rise to alternative forms of publication dissemination, such as preprint servers. Remarkably, physicists and mathematicians have successfully put this idea in practice for the past 25 years with the e-print repository at arxiv.org.
In some scientific communities it is standard procedure to upload a preprint to the arXiv before submitting to a peer-reviewed journal. This makes the arXiv collection a representative source for the publication landscape in those fields, and opens the possibility of running bibliometric analyses. With respect to gender effects, Emma Pierson’s blog post describes differences between women and men authors regarding various metrics, such as author order or collaboration practices. In a recent manuscript, Bonham and Stefan use the arXiv to show gender-related effects in the interdisciplinary field of computational/quantitative biology compared to biology and computer science, finding significant differences regarding the representation of women.
By providing programmatic interfaces, the arXiv facilitates the implementation of this type of large-scale data analyses and the development of creative applications. For the data-backed study of publication patterns (task 2 in the project), we will utilize these APIs to study the effect of gender, especially in areas of physics. The results will complement and extend our previous study on gender and publication patterns in mathematics.
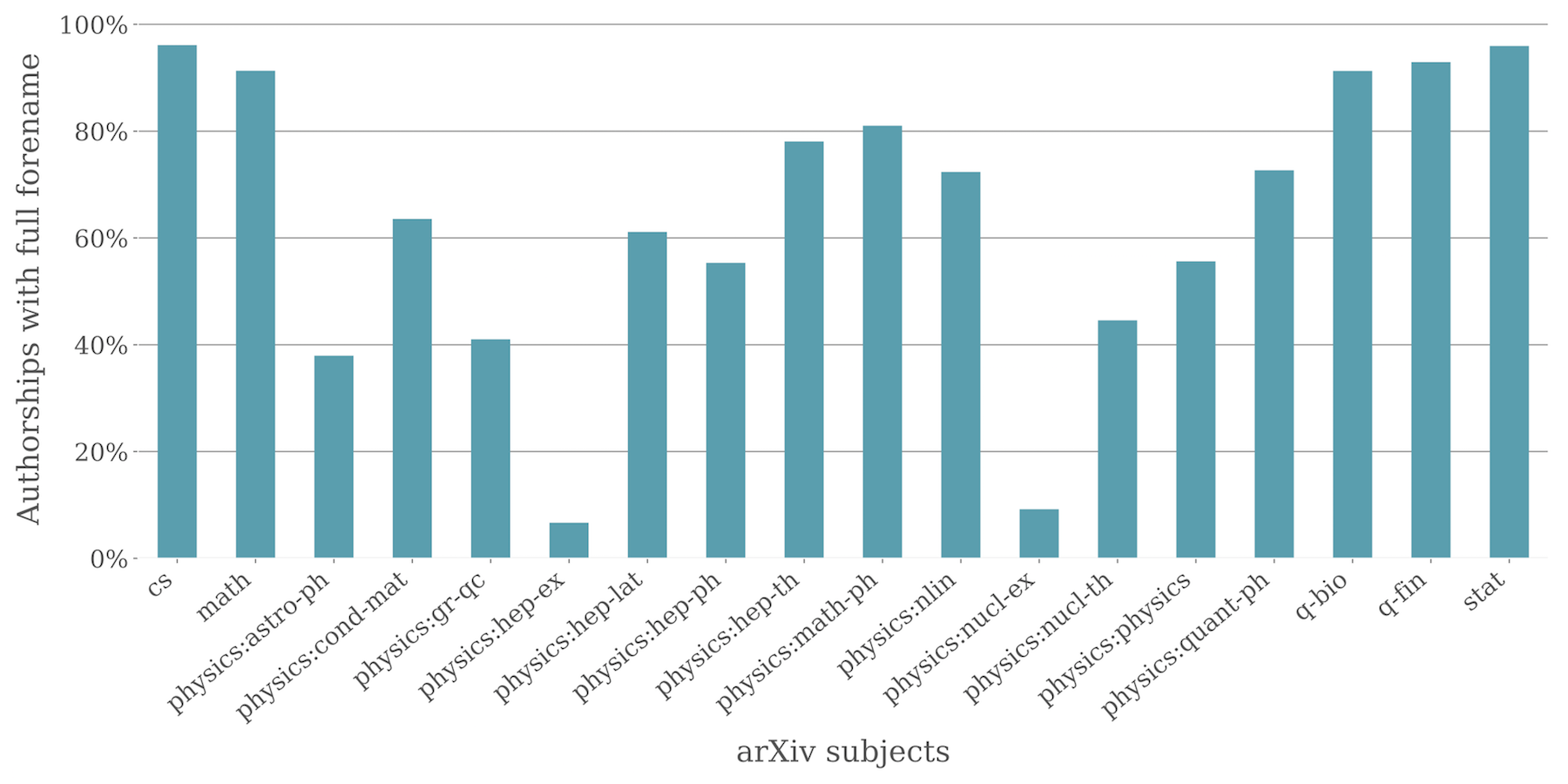
One of the cornerstones of our task is the detection of gender based on authors’ first names. We have already started harvesting data through the OAI-PMH interface and exploring the availability of such data. Fortunately, in many fields the majority of authors provide a full forename rather than an initial. As shown in the plot below, more than 70% of all authors in mathematics, computer science and subfields of theoretical physics use their full names, in contrast to experimental areas such as “high energy physics – experiment” (physics:hep-ex) or “nuclear experiment” (physics:nucl-ex) with less than 10%. This is not surprising considering the number of authors per article in such areas; a preprint with primary category “physics:hep-ex” has on average more than 36 authors1.
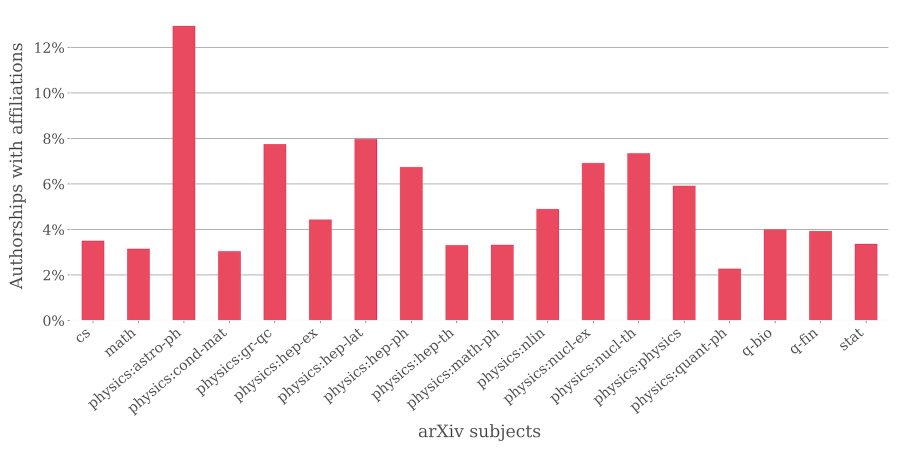
Another highly relevant piece of information for our analyses are the authors’ affiliations in connection with their publications. This data can contribute to the better understanding of the interplay of gender and regional aspects on scientists’ publication behaviour. However, it turns out that only a minority of authors provides their affiliation as metadata. As shown in the figure below, only 4 to 8% of all authorships are supplemented with this information, an exception being the field of astrophysics with approximately 12%. What will help here is to take a look at the full preprint texts: most of them shall contain affiliations, and their extraction would significantly improve the data basis required for a geo-faceted analysis. Luckily, most of the full-texts uploaded to the arXiv are accessible as PDF or TeX/LaTeX source files from which the additional information not contained in the arXiv metadata can be extracted.
In addition to their importance for a geo-faceted analysis of the gender effect, affiliations can strongly help with the task of author-name disambiguation. The ability to distinguish individual scientists allows for deeper analyses by considering the scientific record of individuals rather than the cumulative output of an entire gender. The arXiv does not provide custom author identifiers, and the available metadata does not contain any external ones such as ORCID IDs so far2. Thus the disambiguation of arXiv authors will pose a major challenge to our project that we aim to address using algorithmic approaches from Machine Learning and Natural Language Processing.
Stay tuned!
