Why it is sensible to examine the reliability of gender inference methods
by Helena Mihaljević and Lucía Santamaría
Imagine that you want to teach a computer to figure out the gender of a person based solely on their name. You certainly know that Laura is a ‘she’ while Miguel is a ‘he’. Can one just train a machine to produce the right answer too? A clever set of rules may be crafted, but very soon it will become apparent that exceptions are countless. Enter a multitude of languages, alphabets, and cultures, and the rule-based approach becomes nothing but unfeasible.
And yet a multitude of web services offer to accurately guess the gender of any name. How do they do it? Well, they collect records from baby names lists, censuses, and social media profiles and return the estimated gender, often weighting the certainty of an assignment by the number of times a given gender association is found. The development of this kind of tools has facilitated analyses of social phenomena related to gender and the exposure of gender bias and inequality from assorted data.
Ideally, the preferred approach to such analyses would build on volunteered self-identifications within an inclusive gender classification system. This is seldom possible and generally impracticable though. For the study of most data sources, the name string is the only publicly available information that can be reliably utilized to infer the gender. This is the case when studying the publication records of scientists to understand the sustained gender gap in STEM disciplines, or the absence of women from editorial boards of renowned scientific journals.
But how reliable is the inference really? Most research articles on inferred gendered data present no (sufficient) evaluation of their method, and only rarely do authors describe why they choose a certain tool to assign genders. This is a rather troublesome situation, since inaccuracies at this stage can distort the results enormously. In addition, the verification of the research is often impossible, as most services and data sources for gender inference are closed.
A framework to test and compare gender inference methods
To address this problem we have performed a comprehensive benchmark and comparison of several available gender inference services applied to the identification of personal names. To begin with, we have assembled a curated list of 7,076 persons and their gender, extracted from previously published sources. This ‘gold data’ are the basis to assess the performance of the services, and we have made the set publicly available. We have used the services Gender API, gender-guesser, genderize.io, NameAPI and NamSor, five popular and commonly used tools, to genderize our list of names and have compared the obtained predictions with the manual labels.
When asked for the gender of a name, a service may return ‘female’, ‘male’, or ‘unknown’. The comparison of the inference with the correct gold data label can produce two types of inaccuracies: (1) a mix-up between female and male labels, or (2) an ‘unknown’ response in place of a definite gender. Typical candidates for inaccuracies are unisex names, names whose gender differs by country, and those for which the gender connotation disappears through transliteration or translation. Whether a service assigns a definite label to an otherwise ambiguous name, e.g. predicting that Andrea is female (although typically a male name in Italy) instead of responding with ‘unknown’, is one important difference between services. To quantify the certainty behind a gender assignment, the services provide one or more ‘confidence parameters’ that can be used to build rules to accept the gender classification or rather to replace it by ‘unknown’.
Depending on the requisites of the task at hand, a higher rate of unknowns that ensures fewer mix-ups might be favored, or vice versa. Usually, both aspects are relevant, and a suitable weighting strategy must be identified for each use case to bring the two types of inaccuracies to an acceptable balance. We have combined different error metrics and constraints to define benchmarks for realistic situations. One such scenario is to minimize the proportion of all inaccuracies while keeping the mix-ups between female and male assignments under the threshold of 5%. In another benchmark we minimize the amount of mix-ups while enforcing a definite gender label for at least 75% of all names.
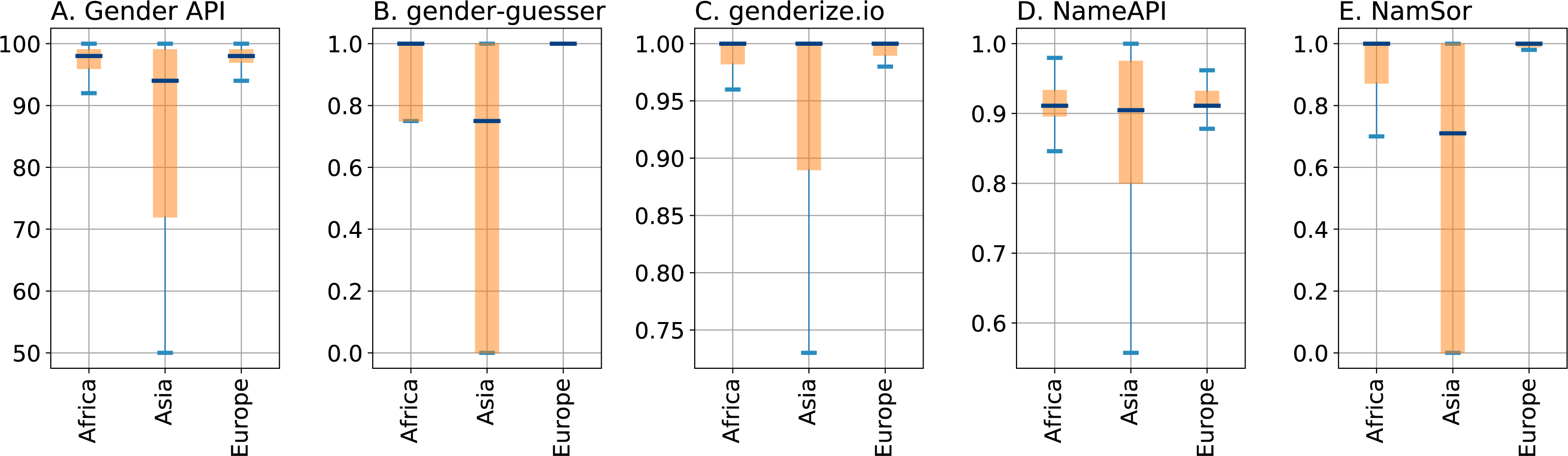
In all our benchmarks, and on almost all sources comprising our test data set, Gender API shows the best results. After optimizing the confidence parameters of all services in a classical setting of training and cross-validation, Gender API achieves an average rate of inaccuracies below 9% under the constraint that the gender be mixed up for less than 5% of all successfully classified names. Likewise, the rate of mix-ups can be kept under 1% while still retrieving a definite gender for more than 75% of all names. Next in performance is NamSor, mostly closely followed by genderize.io, both of which achieve less than 2% mix-ups in the later scenario.
The importance of knowing where names come from
The cultural and geographic origin of names is known to have a great effect on the reliability of gender inference methods. That’s why a crucial aspect of our analysis is the estimation of the names’ origin, which we carry out using NamSor’s origin API. To illustrate this point, we have split the evaluations among African, Asian, and European names. (American and Australian names are considered to descend from the three regions above through migratory phenomena.)
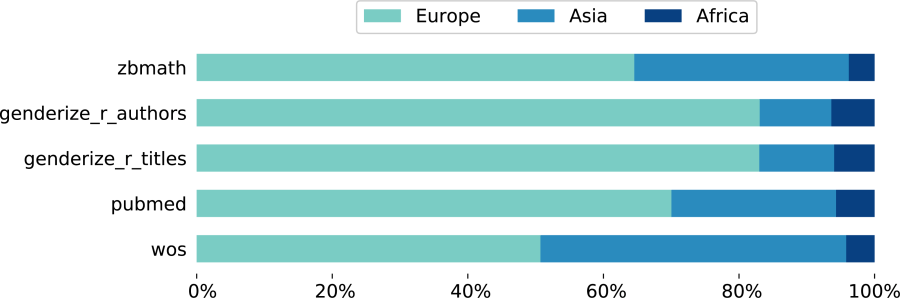
Geographical regions of origin of the personal names from the five sources comprising our test data set
As expected, names of Asian origin are the most difficult to genderize for all services, an issue partly due to loss of information after transliterating into the Latin alphabet. In particular, genderize.io shows large rates of mix-ups on Asian names, despite returning high confidence scores for them. Researchers that trust all responses above a certain confidence value without performing evaluation or parameter tuning on a suitable test data set should hence better be cautious with this service. Contrary to that, Python package gender-guesser, the only open tool of the five under evaluation, shows very few mix-ups (even for Asian names) at the cost of unsatisfactory, low retrieval. After all, this transparent method is ideal to classify the ‘easier names’ before engaging a more complex service such as Gender API or NamSor.
A challenging problem full of nuances
Yet, regardless of benchmarking or parameter tuning, mistakes on gender assignments will undoubtedly remain. In cases like women named Jan, Sy Jye, or Jaime and men named Jen Tien, Lakshi, or Ilke, all services will possibly incur a gender mix-up. The determination of a person’s gender based solely on their name is simply not a straightforward task. It depends on the cultural and regional context; transliteration of names often obfuscate their gender; and many names are simply gender-neutral. Moreover, first names are embedded into the gender binary. But as long as interesting and important data sources are lacking explicit gender labels, name-based gender inference remains the method of choice for plenty of applications, including but not limited to studies of women’s representation in tech, media, or academia. We thus hope that our study will help inform the decision of which gender inference service to choose. Our research, test data set, and code are publicly available; we encourage others to extend the benchmarks to further data sets or create new test cases.
Comparison and benchmark of name-to-gender inference services has been published in https://peerj.com/articles/cs-156.
